Categories
Both Redis and Memurai are incredibly flexible in-memory data stores that are excellent choices for a wide variety of different use cases. A key feature of these systems is that all data resides in memory. This is quite different from more traditional databases that store data on disks or SSDs. It is also one of the reasons why these data stores can deliver the incredible read and write performances that they do. However, the decision to store data in volatile memory poses new challenges with respect to their persistence. Having a good understanding of Redis’ durability guarantees, and its persistence models, is crucial when using Redis in an enterprise environment.
For the purpose of this article, persistence refers to the mechanism used to persist data stored in memory to the host’s file system. Redis supports two very different persistence models: the Redis Database Backup (RDB) model and the Append Only File (AOF) model. The focus of this article will be to discuss the inner workings of these mechanisms and how to decide which one to use.
Redis is compatible with most POSIX systems, such as Linux, *BSD, and OS X. The APIs and examples provided as part of this article also work under Memurai, an actively maintained Windows port of Redis that has been derived from Microsoft’s OpenTech Redis project. Memurai is available free of charge, with commercial subscription licenses available via memurai.com.
Since many developers, the author included, work with Redis under Windows, the terms Redis and Memurai will be used interchangeably in this article. Memurai’s API is 100% compatible with Redis.
Redis RDB – Snapshots-based persistence
RDB is an acronym for “Redis Database Backup.” It is Redis’ solution for point-in-time snapshots. The frequency of the snapshots can be configured using the save configuration directive.
By default, Redis uses the following settings:
save 300 10 # every 5 minutes if at least 10 keys changed
save 60 10000 # every 60 seconds if at least 10000 keys changed
One can also schedule ad-hoc snapshots using the BGSAVE command. Usage of the similarly named SAVE command (in capitals) should be avoided, as it is synchronous and thus will block other clients.
By default, the snapshot will be saved to dump.rdb. An alternative filename can be configured using the dbfilename directive:
dbfilename dump.rdb # The filename where the DB must be dumped
Redis will not write to the configured filename directly. Instead, a temporary RDB file containing the server’s pid will be created and renamed upon success. This ensures the snapshot remains in a consistent state. One can assume that the resulting dump file will not be partially written. Before renaming, data will be committed to the non-volatile storage buffers via fsync / fflush.
Advantages
- Compactness – The resulting snapshot file is mostly just a mapping of keys to values: When inspecting the resulting RDB file using a Hexeditor, it will be noticed that the file is a rather compact representation of the database’s internal dictionary (plus a version prefix and checksum). Redis optionally supports LZF-based compression, which is enabled by default and can further reduce the size of the snapshot.
- Performance – RDB-based compression does not impact on write performance, as snapshots are generated using a background process. There is no additional work that would have to be done on individual writes. However, forking and running the background process can in itself impact performance.
- Faster restarts – On restarts, Redis has to load the entire dataset back into memory. When using RDB, Redis simply has to scan over the existing snapshot and load each KV-pair back into its internal dictionary. This is much faster than recreating the internal dictionaries based on AOF entries (more about this later).
Disadvantages
- Durability – Pure RDB-based persistence can easily result in data loss. Redis itself is a very reliable piece of system software. However, in the real world machines do crash, and hardware failures do occur. Given a large enough deployment, even the most obscure issues and soft errors are going to occur. If one can absolutely not afford to lose individual transactions that occurred after the last successful snapshot, relying solely on RDB for disaster recovery is not going to serve this purpose well.
- Performance – RDB snapshots are generated in background processes, meaning that the server process has to be fork()’ed. This can be quite expensive, since the whole process will have to iterate over the entire dataset and effectively generate a snapshot from scratch every n updates / m seconds. Redis AOF – Append Only File AOF is an acronym for “Append Only File,” which is fairly self-descriptive. This is the second persistence model offered by Redis and it works by appending each operation to a file configured using the appendfilename directive:
appendfilename "appendonly.aof"
If Redis crashes or is for whatever reason unable to persist its internal dictionaries to an RDB snapshot file, Redis can simply replay operations that occurred prior to its shutdown.
This is similar to write-ahead logging (WAL), which is a technique employed by a variety of different database systems to meet strong durability guarantees.
To understand this somewhat better, consider the following example.

Under the “Client” column, one can see commands issued by Redis clients via RESP, e.g., using redis-cli. Under the appendonly.aof column, the content of the AOF file is shown. The third column contains Redis’ current memory layout.
For each command issued by clients, a set of instructions is appended on the AOF file. “SET hello world,” for example, will be serialized as “*3\n$3\nset\n$5\nhello\n$5\nworld.” “*3\n” means that the command that is about to follow accepts two arguments (3-1). In the case of the SET command, those arguments are the key (“hello”) and value (“world”). Each command and argument is prefixed with its length in bytes. “$5\n” means that the subsequent argument is 5 bytes long (“world”).
One can experiment with this by enabling AOF persistence via the appendonly directive and running tail -f appendonly.aof while issuing commands to the Redis server.
appendonly yes
Advantages
- Durability – Every operation is appended to the appendonly.aof file. As such, Redis is able to restore its previous state by replaying the commands listed in the AOF file line by line. This is quite different from RDB-based persistence, where all writes prior to the latest snapshot will be lost. However, there are some nuances around this: committing data to disk after every command via fsync would be prohibitively expensive. As such, Redis defaults to calling fsync at most once per second and one may therefore still end up losing data in the case of, for example, power failures. If the particular use case cannot tolerate this, Redis can be configured to call fsync after every operation via appendfsync always.
- Transparency – Understanding the generated AOF file is trivial compared with the RDB snapshot. The appendonly.aof file can easily be inspected or truncated with a text editor of one’s choice. This can also help during debugging, as the file can be used as a form of log to debug bugs and other issues.
Disadvantages
- File size – appendonly.aof will almost always be significantly larger than the RDB-generated dump.rdb file. This is especially true when doing a large number of writes to the same set of keys. In the above example, we first set the “city” to “Seattle,” then to “London.” Consequently, we append two operations to the AOF file. If we would have generated an RDB snapshot instead, there would have been a single key-value pair and no commands or length prefixes. AOF is able to partially mitigate this issue by compacting the log in the background and rewriting commands (e.g., “INCR counter,” “INCR counter,” “INCR counter” could be rewritten as “SET counter 3”).
- Startup time – In order to restore its previous state, Redis has to replay each and every command listed in the AOF file. Depending on one’s write-load, this can be significantly slower than restoring the state from a simple snapshot file. When using RDB, Redis just has to load each KV-pair into memory – it does not matter how frequently a particular key was updated. This will be quicker than re-executing every command that led to the current state.
- Performance – AOF may be slower than RDB, but it is difficult to say with certainty without running benchmarks for one’s own specific use case. However, what is certainly true is that performance tends to be more predictable and less dependent on the use case’s specific write-load when using RDB. Log compaction As can be seen in the example above, the size of the AOF file is continuously going to grow over time. This can be problematic, especially when dealing with frequently changing data. Supposing that we have a counter service that is bumped for every page view via INCR, then:
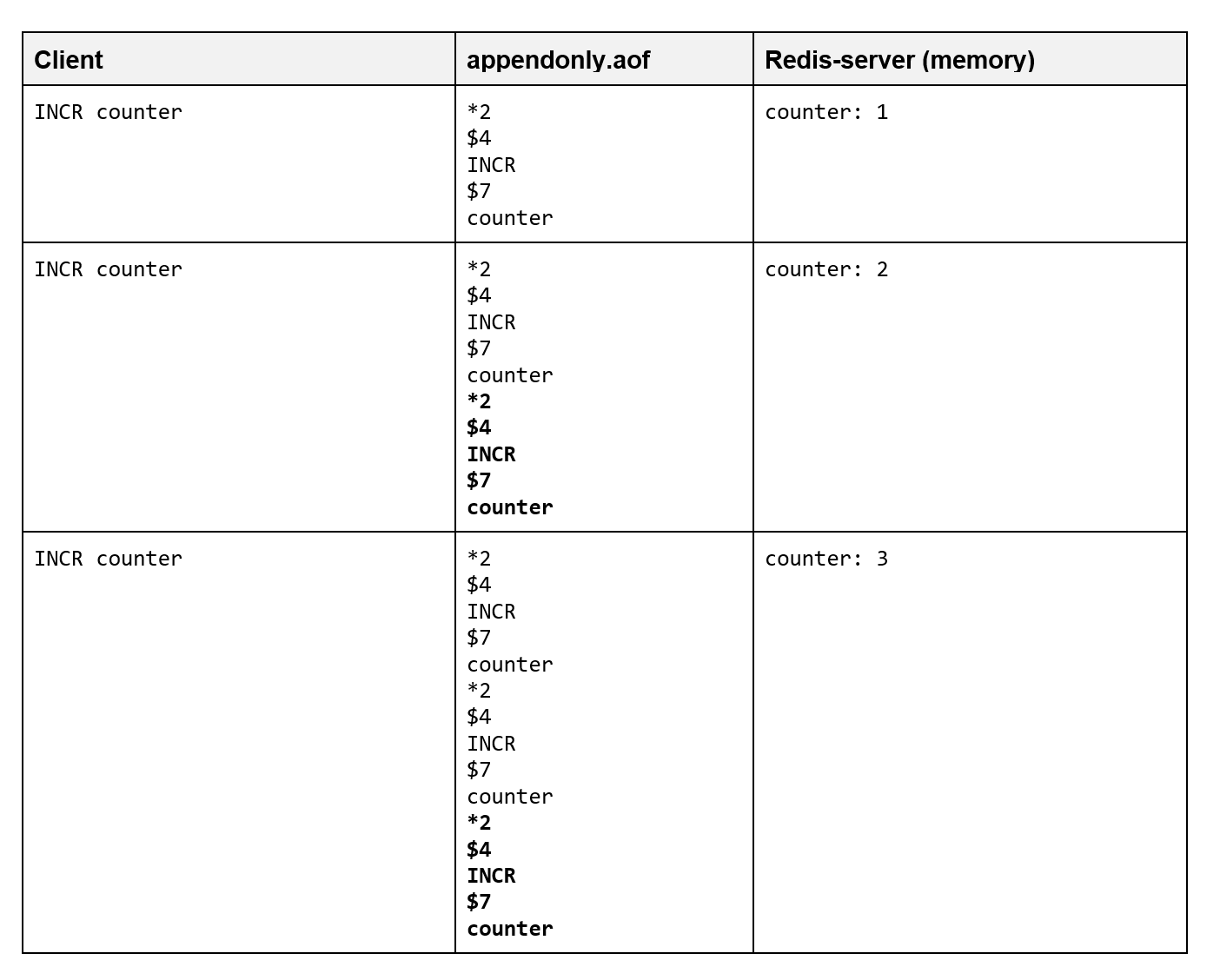
It can be seen that for every bump, we add an additional five lines to the appendonly.aof file. Suppose our Redis instance crashes after 10 million page views. On restart, Redis would effectively have to reevaluate 10 million commands.
As this is neither efficient nor scalable, Redis offers the option to “compact” AOF files. In newer versions of Redis, this is done automatically. Alternatively, one can issue the BGREWRITEAOF command to initiate a corresponding background job:
Background append only file rewriting started
127.0.0.1:6379> quit
alexandergugel@192 redis % tail appendonly.aof
*3
$3
SET
$7
counter
$1
3
In this example, the three INCR commands were rewritten to a single SET instruction.
AOF with RDB-preamble
Redis supports further optimizations for faster log compaction and recoveries. As described above, rewriting AOF instructions can drastically decrease the number of commands. However, Redis needs to execute on startup to restore its previous state, and it is still not nearly as compact as RDB, which is designed first and foremost as a file format for snapshots.
As such, Redis supports a configuration directive called aof-use-rdb-preamble:
aof-use-rdb-preamble yes
When enabled, the appendonly.aof file will be prefixed with an “RDB preamble.”
This preamble will contain a point-in-time snapshot of what Redis stored when the log compaction background job was initiated. Successive commands will be appended to the AOF file as usual – until the next rewrite of the AOF file.
By enabling aof-use-rdb-preamble we reap many of the benefits that come with RDB, while securing better durability guarantees, including:
- Faster restarts – Depending on when the AOF file was rewritten, most of the data will be stored in the RDB preamble. Restoring a state on startup from the RDB preamble is more efficient than having to replay individual commands from an AOF file.
- More compact – The RDB file is a more compact representation than the length prefixed AOF commands and arguments.
- Durability – Commands issued by clients can still be appended to the AOF file right after being received, thus ensuring commands that are not part of the snapshot can be replayed on startup.
The main drawback of using the RDB preamble is the sheer complexity that comes with it: One can no longer just inspect the AOF file when problems occur. Redis provides utility scripts for fixing corrupted AOF files, and newer versions even fix certain issues on startup. However, there is a certain complexity that comes with rewriting AOF files, which should not be underestimated. Certain edge cases have to be considered and carefully thought about, e.g., whether or not there is enough space on the volume on which the AOF file is stored.
No persistence
Redis can also be used as an LRU-based caching solution, e.g., as a drop-in replacement for Memcached. In such cases, persisting data to disk might not be required. This can be configured by setting appendonly no and removing all save directives from one’s config file:
appendonly no
save ""
RDB deep dive
It is not necessary to have a deep understanding of the inner workings of RDB to appreciate its limitations. However, Redis’ source code is quite accessible. Understanding how snapshots are generated and written to disk can be rather illuminating.
The entry point into the RDB persistent model is the rdbSave function in rdb.c. The function is responsible for creating the temporary file into which the snapshot will be written, as well as renaming the temporary file to the dbfilename described above:
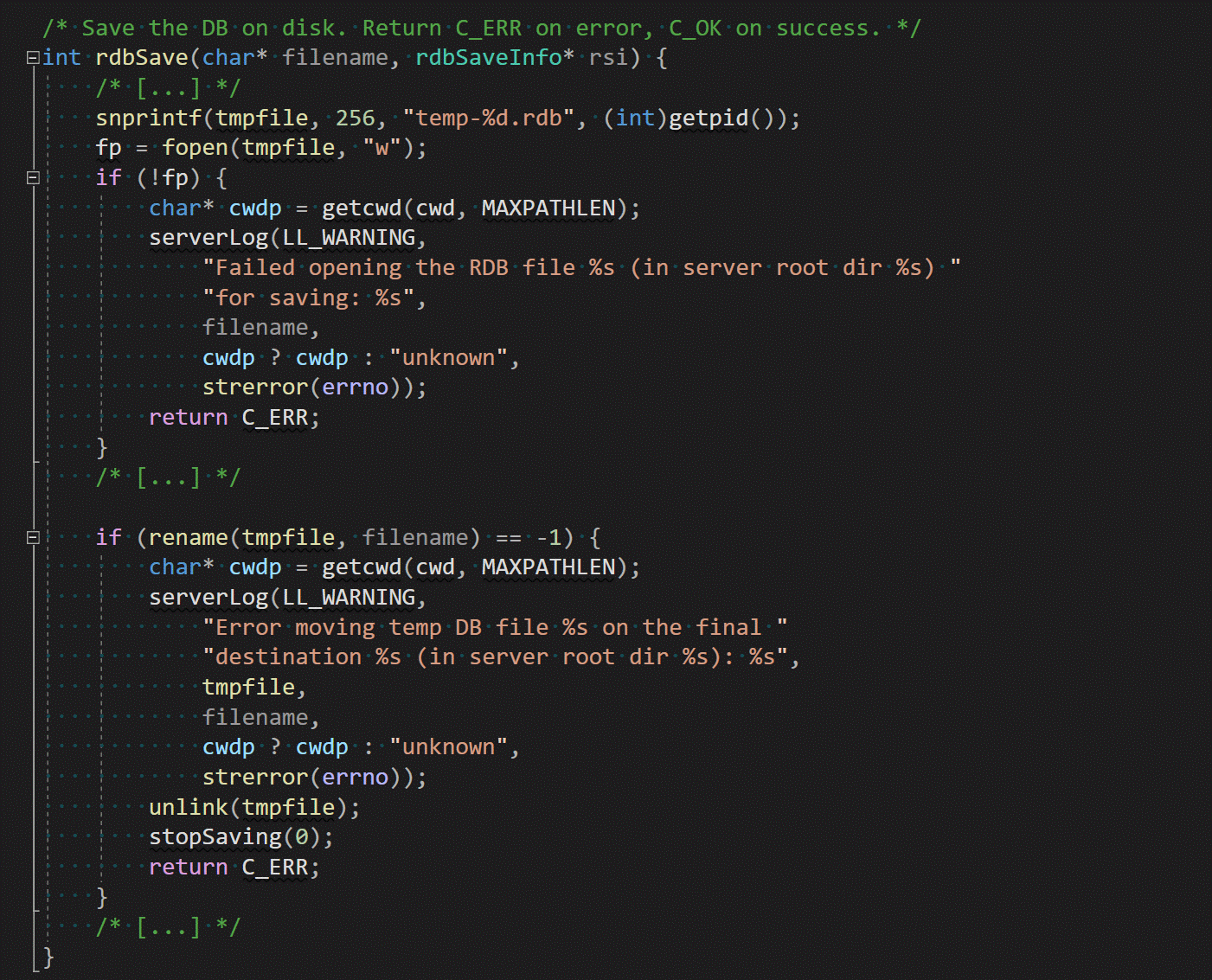
After the file pointer for the temporary file has been obtained, Redis delegates the actual serialization to corresponding rio* functions. rio.c is a clever abstraction around streams that enables Redis to share the same serialization code for in-memory buffers and files. It provides a number of additional utilities, such as the ability to easily compute checksums for already processed data.
The actual serialization code is in rdbSaveRio, which operates on the aforementioned rio stream, rather than on the raw file descriptor:
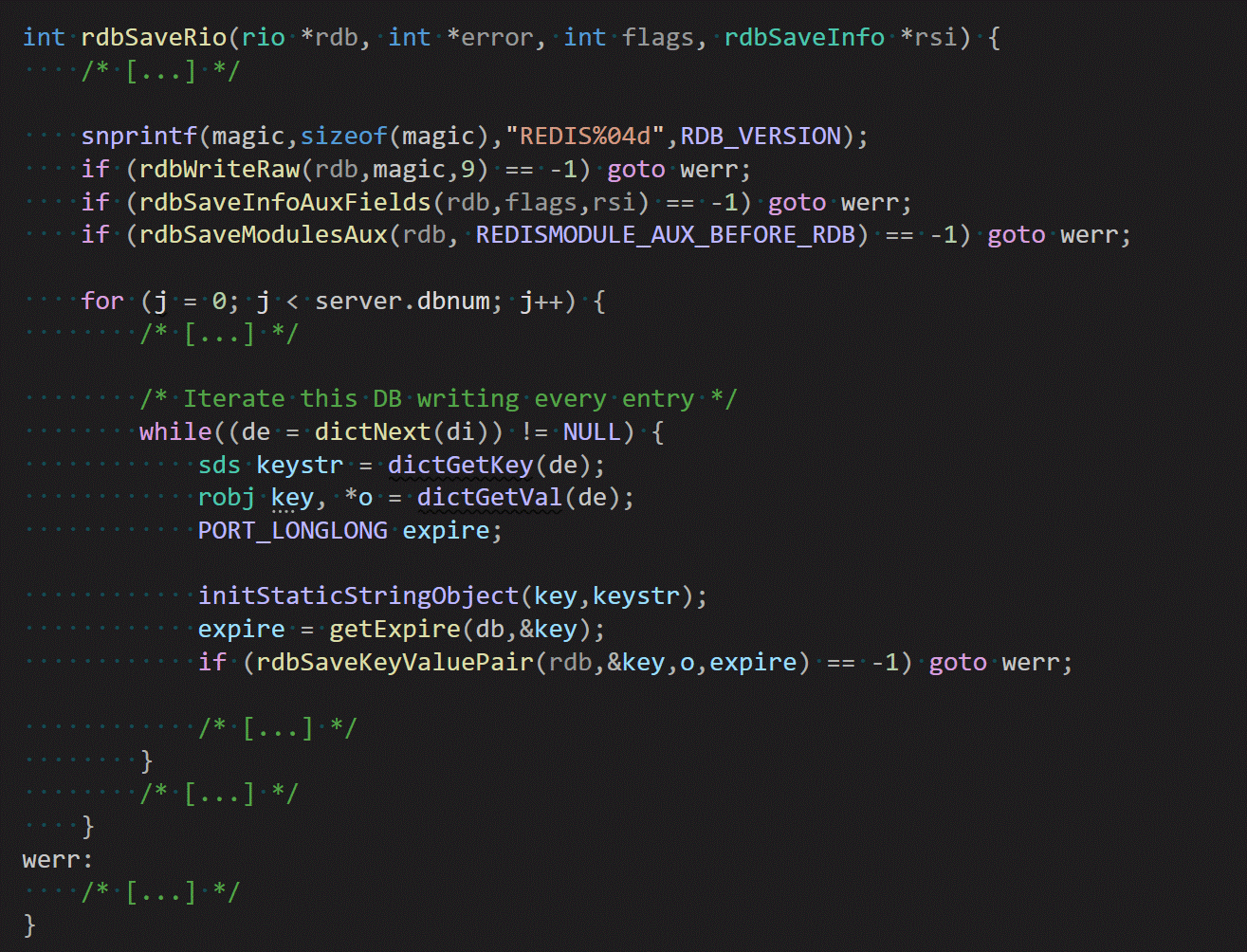
The overall serialization logic is relatively straightforward. There are many moving pieces and nuances in the omitted code seen above, but on a high level, it works as follows:
- We prefix the file with a file signature consisting of the name “REDIS” in ASCII followed by the version number of the running server.
- We write rdbflags to the rio stream. rdbflags is used as a bitmask to configure various options around how the snapshot should be generated:

- We iterate over all databases (see SELECT for details on what this means).
- For each database, we obtain an iterator that is used for sequentially going over all relevant key-value pairs.
- For each key-value pair, we call rdbSaveKeyValuePair, which serializes the specified key and value into a corresponding binary representation that can be persisted to disk. The serialization format depends on the type of value being processed.
Summary
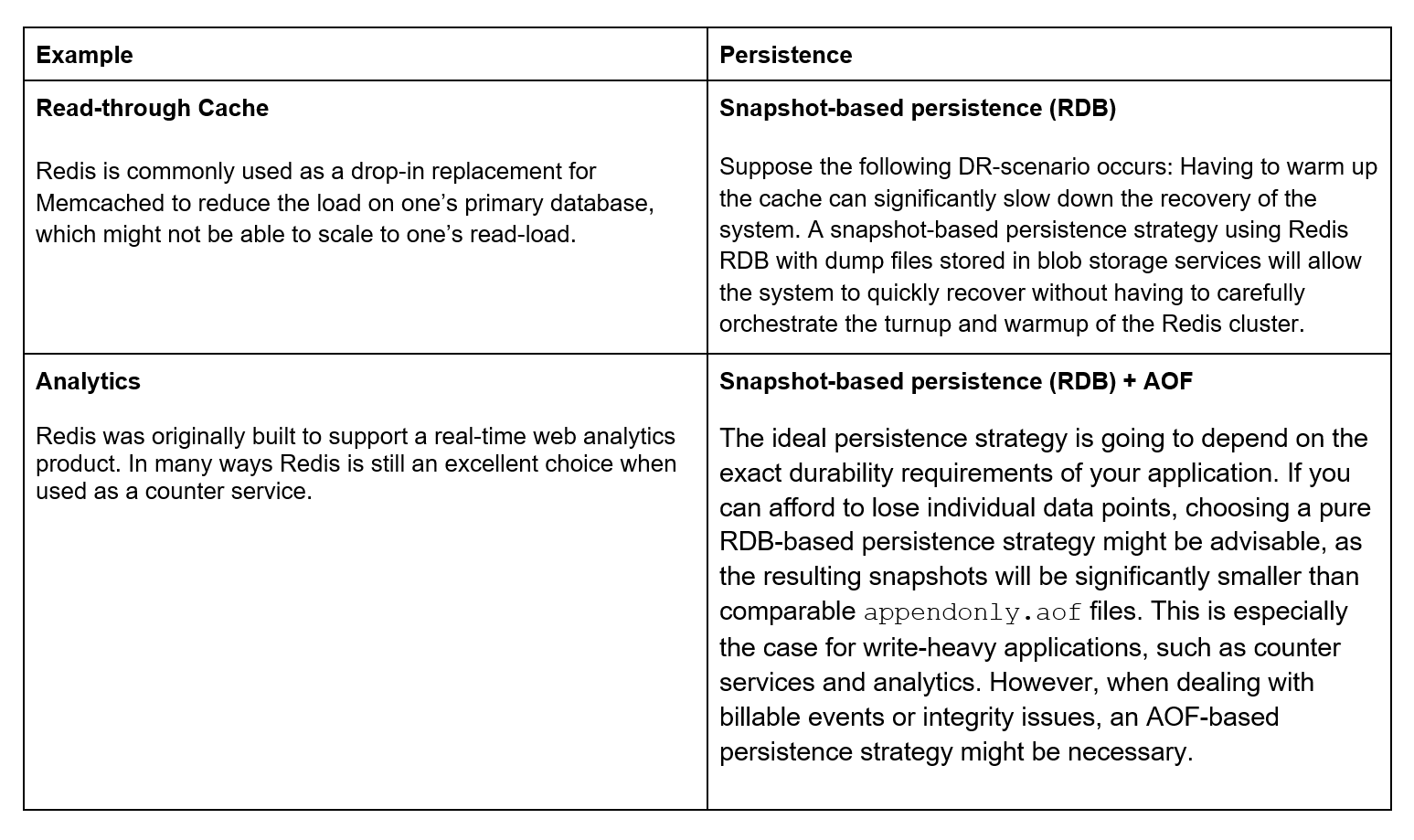
Thus, what should one use? RDB or AOF? It is most likely that some combination of both might best fit one’s use case. The following are some pointers to assist with the decision-making process:
- If one cannot tolerate any data loss ever, use AOF-based persistence with appendfsync always. This will ensure that the .aof file will be committed to disk after each operation. Even in case of power failures, Redis will be able to restore its state by replaying the commands listed in the file. If this turns out to be prohibitively expensive, one can relax durability guarantees by tweaking appenddsync.
- If one can afford to lose the last X seconds or Y operations, select RDB-based persistence with corresponding save directives.
- If some data can be lost while maintaining acceptable performance, but it would be preferable not to lose such data, an appropriate combination of AOF- and RDB-based persistence should be used. Even when using AOF, it is advisable to make periodic snapshots via RDB for backups.
Redis is a trademark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by Memurai is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and Memurai

